Storage Systems / Crash Safety
AccretionDB
The point of the engine is not simply faster writes. It is to reduce SSD write amplification without weakening the durability story.
AccretionDB is a correctness-first WiscKey-style key-value engine built in C++20. Keys and pointers stay in the LSM path, raw values move into an append-only value log, and visibility is delayed until the write, log, and manifest boundaries make recovery unambiguous.
Write Amplification
2.07x
repo-reported random-write workload
Random Read P50
11us
successful hits still end in the value log
Strict Write Rate
767 ops/s
WAL and value-log durability boundaries kept explicit
The Core Problem
Write amplification kills SSDs.
Traditional LSM engines like LevelDB and RocksDB write values into SSTables alongside keys. During compaction, those values are rewritten repeatedly as data moves between levels. A single 100-byte value might be physically written 10–30 times over its lifetime.
AccretionDB implements the WiscKey paper architecture: separate keys from values entirely. Keys and pointers live in the sorted LSM path. Values live in an append-only Value Log. Compaction now shuffles 20-byte pointers, not full payloads.
The result is write amplification anchored at ~2.0x — a mathematically un-optimizable floor for this layout. Not 10x. Not 30x. Two.
Traditional LSM
10–30x
write amplification
AccretionDB (WiscKey)
2.07x
write amplification
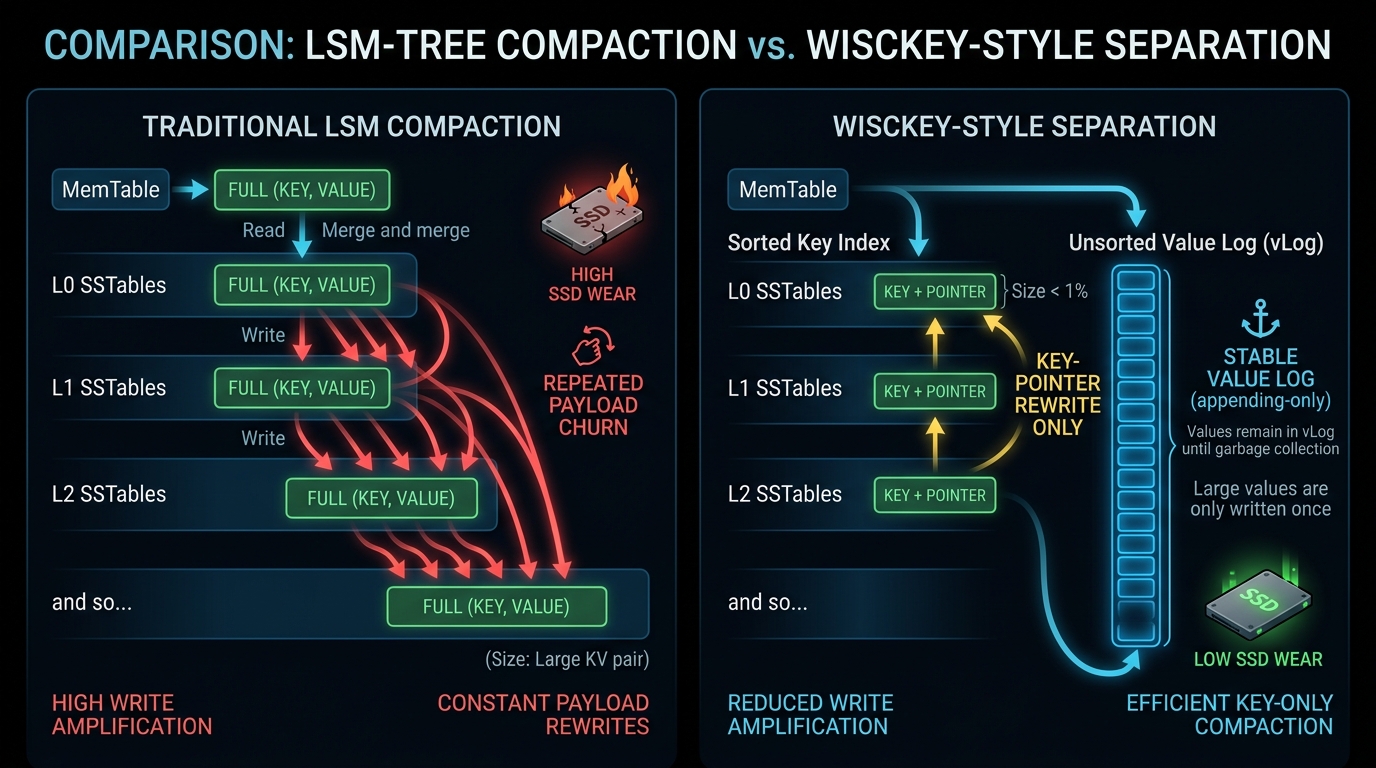
The core motivation: separating values from the sorted path eliminates compaction's biggest cost.
Architecture
System Components
Eight components. Each owns a precise correctness boundary. Each has a defined failure mode.
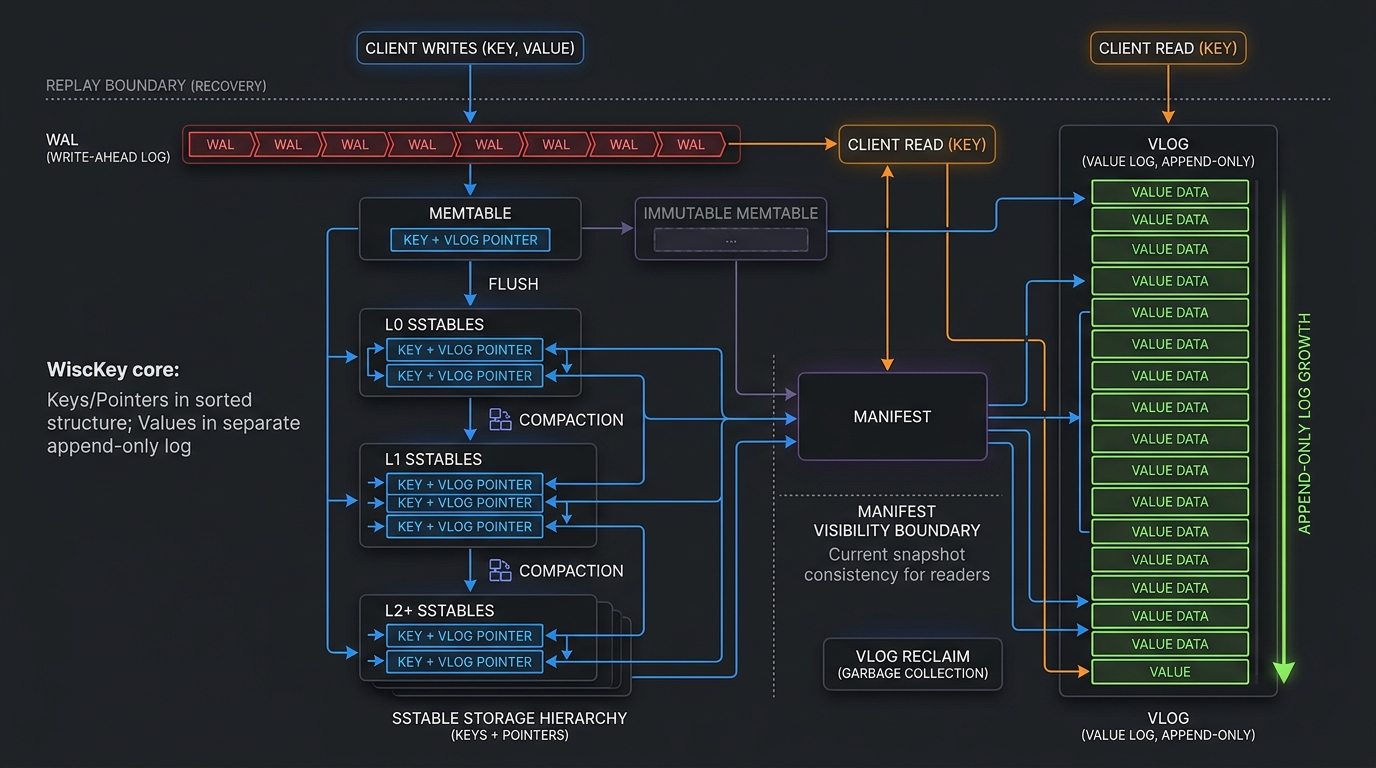
Full storage engine: WAL → Memtable → SSTable flush → L0/L1 compaction, with Value Log separation throughout.
| Component | Responsibility |
|---|---|
| WAL | Durability for in-flight writes |
| VLog | Stores raw values in append-only format |
| Memtable | In-memory sorted key→VLogPointer map |
| SSTable | Persistent sorted key→pointer files with embedded Bloom Filter |
| Manifest | Tracks which SSTables belong to L0 and L1 |
| Compaction | Merges all L0 files + overlapping L1 files into new non-overlapping L1 files |
| GC | Reclaims stale values from VLog by scanning the LSM tree |
| Bloom Filter | Probabilistic membership test per-SSTable |
Write Path
The ordering is not arbitrary — violating it causes data loss.
Every put(key, value) follows this exact 5-step sequence. Each step answers a different crash-recovery question.
WAL.append(key, value)Full record with CRC32 checksum
WAL.sync()fsync — key is now durable on disk
VLog.append(value)Returns VLogPointer {file_id, offset, length}
VLog.sync()fsync — pointer is now safe to reference
Memtable.put(key, pointer)Commit point — key becomes readable here
Delete Path
delete_key(key) appends a tombstone record with value_size = 0xFFFFFFFF to the WAL and inserts a sentinel VLogPointer with offset = UINT64_MAX, length = 0. The tombstone propagates through flush and compaction — never silently dropped.
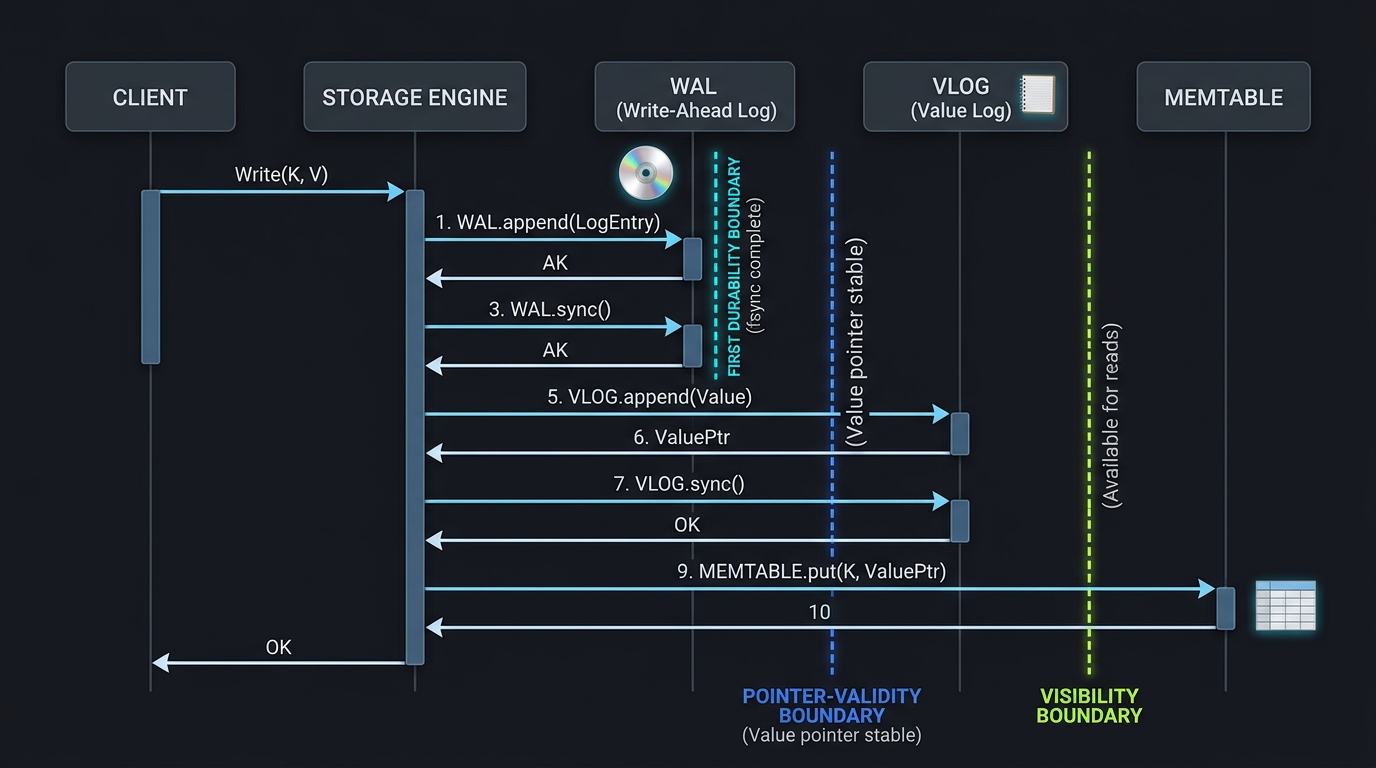
The 5-stage write path. Each sync boundary is a durability guarantee, not an implementation detail.
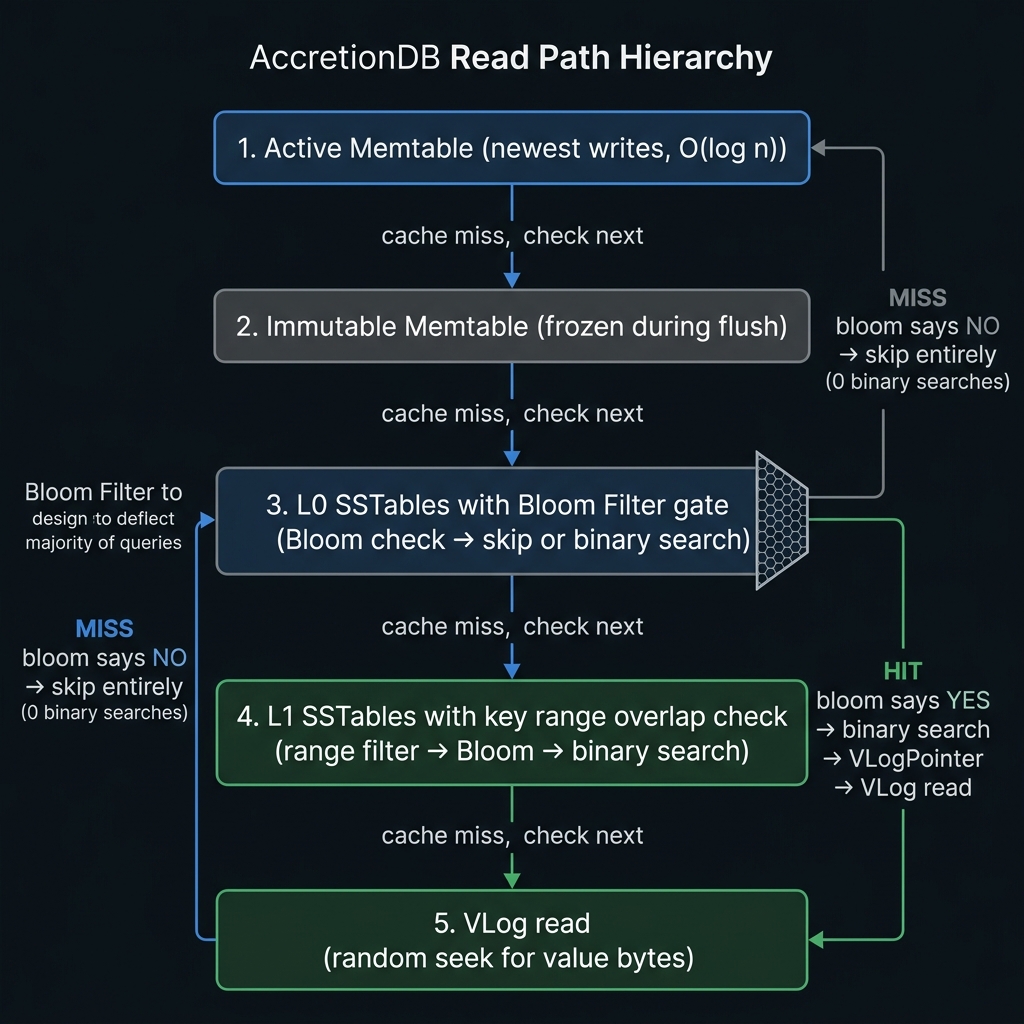
Read hierarchy from newest to oldest: Memtable → Immutable → L0 SSTables → L1 SSTables. Bloom Filters skip binary searches entirely for missing keys.
Read Path
Every get() walks this hierarchy, stopping at the first match.
Active Memtable
In-memory, newest writes first
Immutable Memtable
Frozen during flush, still in-memory
L0 SSTables (newest → oldest)
Bloom check → skip entirely if NO → binary search if maybe
L1 SSTables (range overlap)
Key range intersection → Bloom check → binary search → VLog read
Return not-found
Key does not exist anywhere in the engine
Bloom Impact
With 10 L0 files and 1% FP rate, a missing-key lookup drops from 10 binary searches to ~0.1 average. k=7 hash functions via derived double-hashing.
Tombstone Safety
If any level returns is_tombstone() = true, the read immediately returns not-found. Deleted keys are never resurrected by older levels.
Compaction
Merges L0 into L1. Correctness here is non-negotiable.
Tombstone Safety
If a tombstone for key X exists in L0 and key X also exists in an L1 file not included in this compaction, dropping the tombstone would resurrect the deleted key. Tombstones are only dropped when no version of the key exists in the input L1 files.
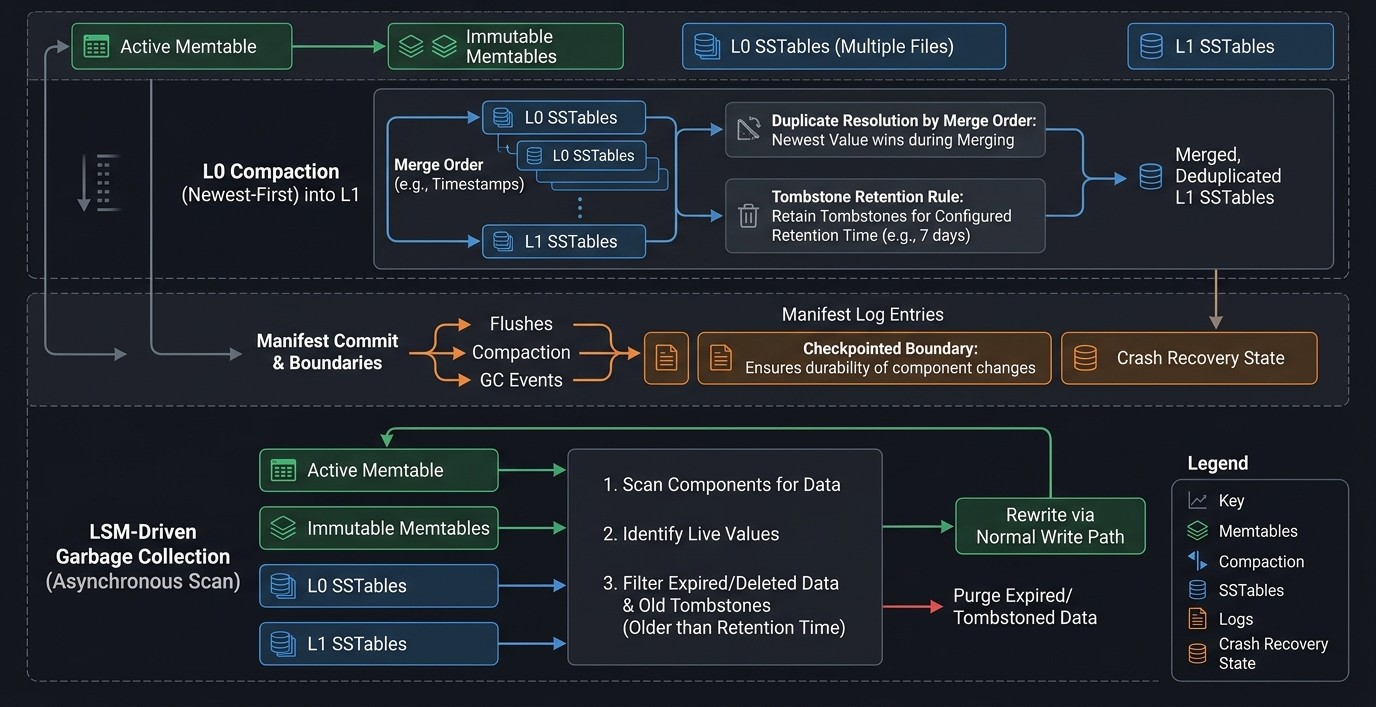
L0→L1 compaction: newest-to-oldest K-way merge with atomic manifest commit. Tombstone safety is a correctness invariant, not a heuristic.
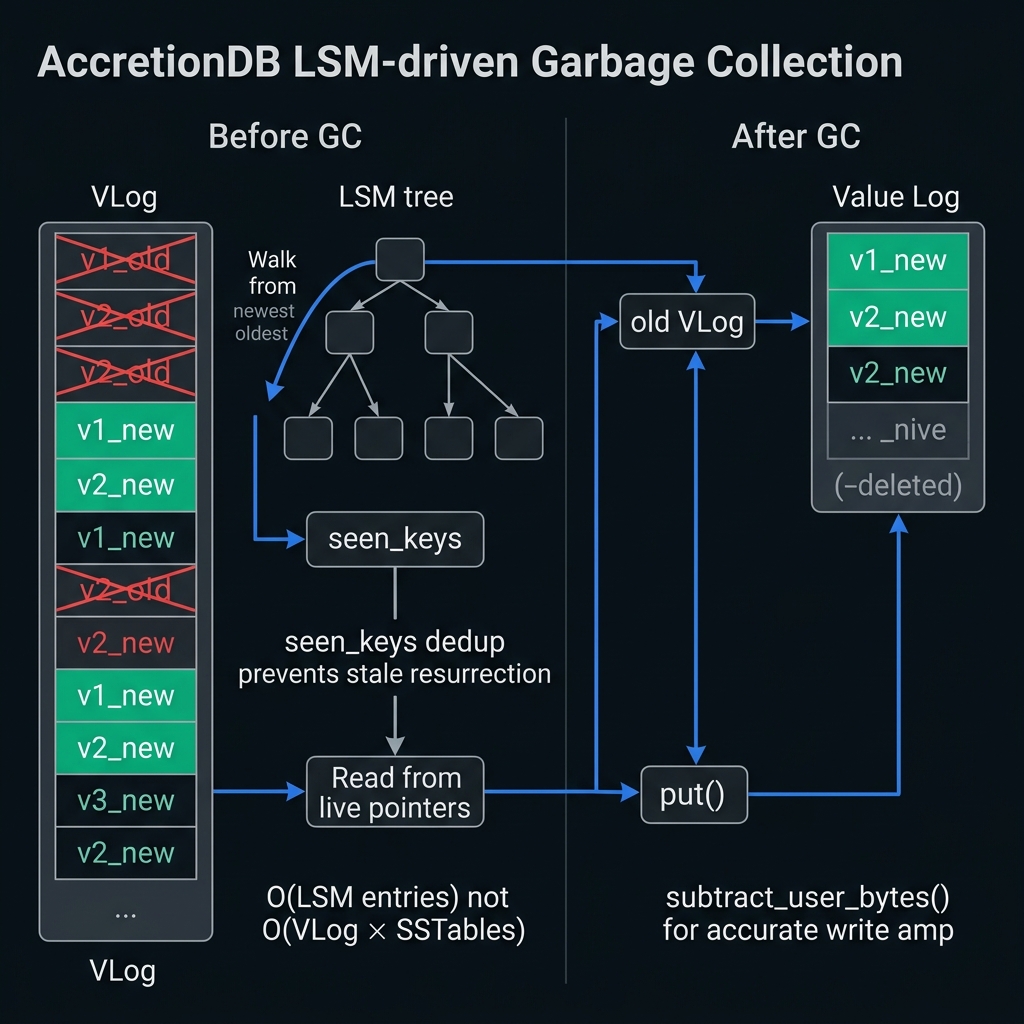
LSM-driven GC: walks the sorted tree to find live pointers, then rewrites values through the standard write path. O(LSM entries), not O(VLog × SSTables).
Value Log GC
LSM-driven GC, not VLog-scanning GC.
Why Naive VLog-Scanning Fails
A naive approach would iterate the VLog and check if any SSTable still points to each value. This requires storing keys in the VLog (violating value-only semantics) and is O(VLog × SSTables). AccretionDB's approach is O(LSM entries) and works with a pure value-only VLog format.
Crash Recovery
A crash at any point leaves a consistent state.
On startup, KVStore::recover() executes four phases in strict order. Recovery is deterministic and complete.
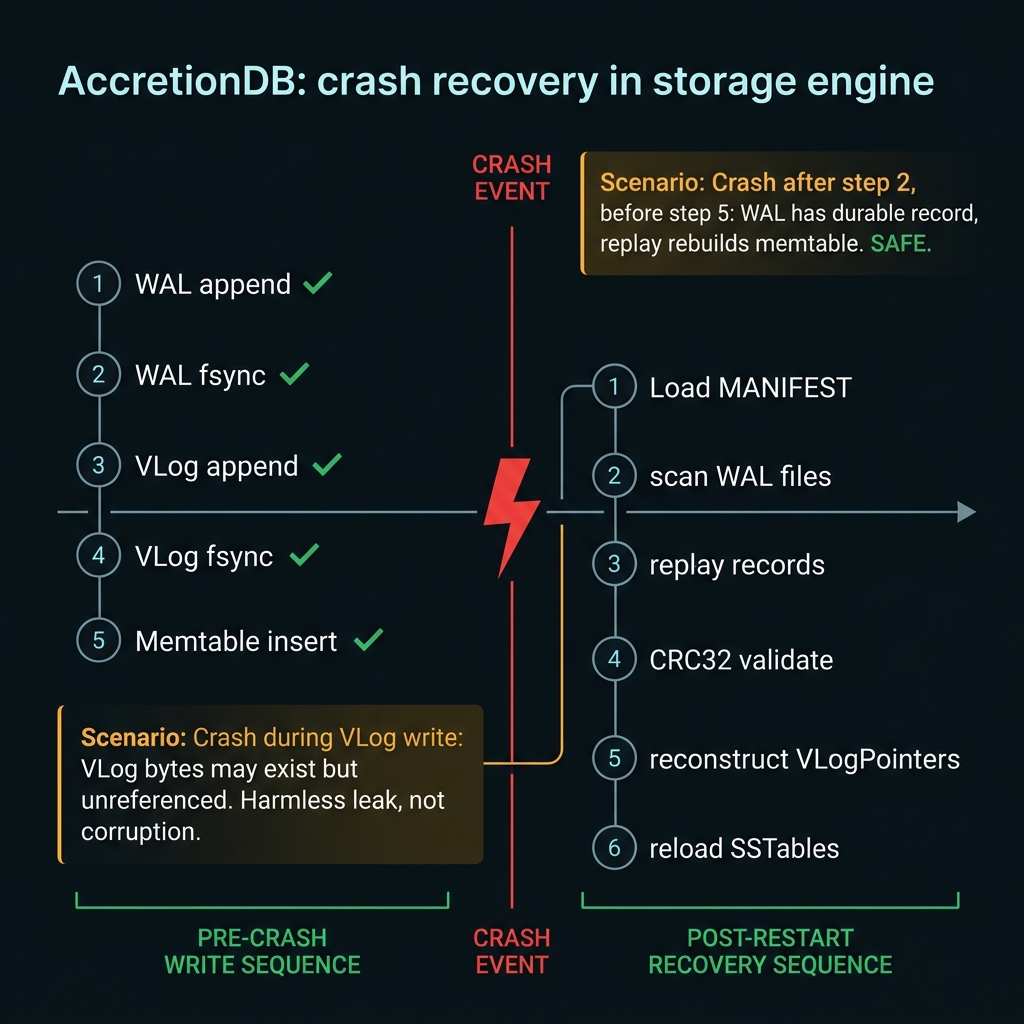
Four-phase recovery: load manifest, scan WAL files by sequence, replay records with CRC32 validation, load SSTables.
01
Load Manifest
Reads MANIFEST file to discover valid SSTables in L0 and L1. Temp files (.tmp) are ignored.
02
Scan WAL Files
Discovers all wal_NNNNNN.log files, sorts them by monotonic sequence number.
03
Replay Each WAL
Reads key_size, value_size, checksum, key, value. Validates CRC32. Reconstructs VLogPointer and inserts into memtable. Stops at first tainted record.
04
Load SSTables
For each sequence in manifest, calls SSTableReader::load() which validates footer checksum and initializes the Bloom Filter.
System Guarantees
| No data loss after put() returns | WAL is fsync'd before memtable update |
| Crash recovery correctness | WAL replay reconstructs memtable; manifest atomic rename protects SSTable visibility |
| Tombstone visibility | Tombstones short-circuit reads at every level; never dropped during compaction unless safe |
| Newest-write-wins | Compaction iterates newest-to-oldest with std::map::insert semantics |
| GC cannot resurrect deleted keys | seen_keys set ensures only newest version per key is rewritten |
| Bloom Filters never cause false negatives | may_contain() defaults to true on failure; bloom bytes included in SST checksum |
| Manifest atomicity | write temp → fsync → atomic rename; crash leaves either old or new, never partial |
| VLog format invariant | VLog stores [value_size][value_bytes] only — no keys. GC uses LSM scan, not VLog scan |
| Backpressure | Writes stall when L0 count exceeds 15; compaction runs synchronously before proceeding |
Engineering Honesty
7 Real Bugs Found, Fixed, and Documented
These are actual bugs discovered and fixed during development, in chronological order. Not hypothetical edge cases. Not textbook examples. Real failures that surfaced under real conditions.
WAL Rotation File Descriptor Leak
Symptom
After WAL rotation, the old WAL file could not be deleted — std::filesystem::remove threw ERROR_SHARING_VIOLATION.
Root Cause
The old WAL file descriptor was closed by the destructor, but Windows does not allow deletion of a file with any open handle. rotate_wal() briefly held both file descriptors simultaneously.
Fix
Switched to create-before-delete rotation: create new WAL, fsync it, swap the pointer, then explicitly destroy the old WAL object before attempting deletion.
// NEW: create-before-delete auto new_wal = std::make_unique<WAL>(next_id); new_wal->fsync(); std::swap(wal_, new_wal); new_wal.reset(); // destructor closes old FD std::filesystem::remove(old_path); // safe
On Windows, file handle semantics differ fundamentally from POSIX. unlink on Linux removes the directory entry while the FD stays valid; Windows refuses to delete files with any open handle.
GC Stale Pointer Resurrection
Symptom
After GC, a key that had been overwritten would occasionally return its old value.
Root Cause
The GC was iterating the LSM tree but not tracking which keys had already been seen. Key X in both L0 (new pointer) and L1 (old pointer) would be rewritten twice — the L1 version's put() overwrote the L0 version.
Fix
Added a seen_keys set to the GC scan. The LSM is iterated strictly newest-to-oldest. Once a key is in seen_keys, all older occurrences are skipped.
std::set<std::string> seen_keys;
for (auto& [key, ptr] : lsm_newest_to_oldest) {
if (seen_keys.count(key)) continue;
seen_keys.insert(key);
if (!ptr.is_tombstone()) live.push_back({key, ptr});
}LSM iteration order is a correctness property, not a performance optimization.
Compaction Chunk Size Undercount
Symptom
Compacted L1 SSTables were larger than expected, occasionally exceeding the 4 MiB flush threshold.
Root Cause
The chunk size accumulator used key.size() + 16 (old VLogPointer size) instead of key.size() + 20 (actual: uint32_t file_id + uint64_t offset + uint32_t length = 20 bytes).
Fix
Corrected the per-entry byte estimate to key.size() + 20.
// OLD chunk_size += key.size() + 16; // NEW — matches actual serialization layout // uint32_t file_id(4) + uint64_t offset(8) + uint32_t length(4) = 20 chunk_size += key.size() + 20;
Serialization estimates must match actual serialization. Off-by-4 becomes off-by-4000 over 1000 entries.
Bloom Hash Seed Independence
Symptom
Higher-than-expected false positive rates in Bloom Filters, especially with short keys.
Root Cause
Two independent MurmurHash64A calls with different seeds gave no theoretical guarantee of hash independence — the two outputs could correlate for certain key distributions.
Fix
Switched to derived double hashing: single base hash, h2 derived via bit rotation. Also fixed integer promotion UB in the bit-set operation.
// OLD: correlated uint64_t h1 = MurmurHash64A(key, 0x9747b28c); uint64_t h2 = MurmurHash64A(key, 0x12345678); // NEW: derived double hashing uint64_t base = MurmurHash64A(key, 0x9747b28c); uint64_t h1 = base; uint64_t h2 = (base >> 33) | (base << 31);
Two hashes with different seeds is not the same as two independent hashes. The Kirsch-Mitzenmacker theorem works with derived hashes.
Benchmark Directory Cleanup Race
Symptom
Benchmark runs would intermittently crash with filesystem error: cannot remove on Windows.
Root Cause
std::filesystem::remove_all(bench_dir) was called while the KVStore destructor was still running — file handles for WAL, VLog, and SST files were not yet closed.
Fix
Scoped KVStore inside a {} block. The destructor completes before remove_all is called.
// OLD: destructor races with remove_all
KVStore db(bench_dir);
run_benchmark(db);
std::filesystem::remove_all(bench_dir); // CRASH
// NEW: explicit scope
{
KVStore db(bench_dir);
run_benchmark(db);
} // destructor closes all FDs
std::filesystem::remove_all(bench_dir); // safeRAII guarantees are about scope, not about the next line. If cleanup depends on destruction, enforce destruction order with explicit scoping.
Write Amplification Inflation from GC
Symptom
Reported write amplification was 3-5x higher than expected, even with minimal compaction.
Root Cause
GC rewrites live values through put(), which increments user_bytes_written. GC writes are internal and should not count as user-initiated writes.
Fix
After each GC put(), call subtract_user_bytes(key.size() + value.size()) to remove the internal write from user metrics.
for (auto& [key, value] : live_values) {
db.put(key, value); // increments user_bytes_written
// subtract internal bytes to keep WA honest
db.subtract_user_bytes(key.size() + value.size());
}Amplification metrics are only meaningful if the denominator accurately reflects user intent.
SSTable Checksum Not Covering Bloom Section
Symptom
A corrupted Bloom Filter byte array would silently pass SSTable load validation.
Root Cause
The original CRC32 was computed only over the data section. Bloom bytes sat between data and footer but were not included in the checksum.
Fix
Changed checksum computation to cover data section + bloom section as a single contiguous payload.
// OLD: only data section uint32_t crc = crc32(data_bytes); // NEW: data + bloom together uint32_t crc = crc32(data_bytes); crc = crc32_extend(crc, bloom_bytes); footer.checksum = crc;
If you add a section to a file format, update the integrity check to cover it. Unchecked bytes are undetected corruption vectors.
Bloom Filter Design
Per-SSTable. Embedded. mmap-backed for large filters.
Each SSTable contains an embedded Bloom Filter built during flush or compaction. The filter uses derived double-hashing from a single MurmurHash64A call — avoiding correlated seeds while keeping the hot path to a single hash computation.
Sizing is optimal: given n keys and a 1% target false positive rate, m bits = -n × ln(0.01) / (ln(2))², k hash functions = (m / n) × ln(2). The bit array is rounded to the nearest byte boundary.
Hashing Scheme
base = MurmurHash64A(key, 0x9747b28c)
h1 = base
h2 = (base >> 33) | (base << 31) // bit rotation
for i in [0, k):
bit_index = (h1 + i * h2) % mSSTable Layout
[Data Section: sorted key-pointer entries ]
[Bloom Section: uint32_t k + bit array ]
[Footer: entry_count | bloom_offset ]
| bloom_size | CRC32 checksum ]
↑ covers data + bloomSmall Filters (< 1 MB)
Heap memory (std::vector)
Large Filters (≥ 1 MB)
mmap / MapViewOfFile

Bloom Filter embedded in SSTable binary format. False negatives are impossible by construction — a broken filter falls back to checking everything.
Performance
Benchmarks Executed on Windows NVMe SSD
20,000 operations per workload. 100-byte values. Cold runs: empty OS page cache. Warm runs: populated LSM state.

Full benchmark suite: write/read/mixed workloads across cold and warm cache states.
Benchmark Results
| Workload | Cache | Throughput | P50 | P95 | P99 | Write Amp | Read Amp |
|---|---|---|---|---|---|---|---|
| Random Write | Cold | 767 ops/s | 1.27 ms | 1.50 ms | 1.66 ms | 2.07x | — |
| Random Write | Warm | 762 ops/s | 1.27 ms | 1.51 ms | 1.72 ms | 2.07x | — |
| Sequential Write | Cold | 743 ops/s | 1.29 ms | 1.51 ms | 3.42 ms | 2.04x | — |
| Sequential Write | Warm | 519 ops/s | 1.34 ms | 4.42 ms | 4.71 ms | 2.04x | — |
| Random Read | Cold | 80,000 ops/s | 11 µs | 17 µs | 25 µs | 0.00x | 1.00x |
| Random Read | Warm | 78,740 ops/s | 11 µs | 19 µs | 24 µs | 0.00x | 1.00x |
| Mixed (70R/30W) | Cold | 2,314 ops/s | 36 µs | 1.44 ms | 1.58 ms | 2.07x | 1.00x |
| Mixed | Warm | 2,302 ops/s | 36 µs | 1.43 ms | 1.58 ms | 2.07x | 1.00x |
The 1.3ms Write Latency Floor
Durability over Throughput
Throughput is hard-capped at ~700 ops/s because the system enforces strict durability. Every put() pays the absolute hardware cost of two sequential fsync() barriers — one for the WAL, one for the Value Log. 1.27ms is the physical IO limit for unbatched, single-threaded writing on this NVMe drive. CPU tuning is irrelevant here until WAL group commit is introduced.
The 2.0× Write Amplification Boundary
The WiscKey Advantage
Write amplification remains mathematically anchored at ~2.04×–2.07× even under heavy sequential overlap. In LevelDB, sequential overwrites force compaction to repeatedly rewrite 100-byte values, compounding write amplification to 10–30×. AccretionDB decouples keys from values — compaction only shuffles 20-byte pointers. The 2.0× is an un-optimizable floor, but it brilliantly insulates the SSD from compaction wear.
The Read Amplification Illusion
Why 1.0× is Misleading
Read amplification tracks (SST Searches + VLog Reads) / get(). Because per-SSTable Bloom Filters intercept missing keys instantly, overlapping L0 SSTables incur 0 searches. Successful reads hit exactly 1 search + 1 VLog read = 1.00×. However, WiscKey shifts structural read depth into physical random IOPS — every read requires a random disk seek against the VLog unless shielded by a block cache.
Warm Sequential Degradation
Compaction Backpressure Signature
Cold sequential throughput: 743 ops/s. Warm throughput: 519 ops/s with P99 spiking to 4.71ms. This is the statistical signature of a synchronous state-machine lock. The warm run boots by recovering 20,000 keys from WAL. When the next 20,000 sequential writes stream in, they instantly breach the 15-file L0 limit. The main thread halts put() ingestion to perform synchronous K-way merges against heavily populated L1 files, destroying the P99 tail.
Tradeoffs
| Decision | Why | Cost |
|---|---|---|
| Single-threaded | Eliminates concurrency bugs; all invariants hold trivially | No parallel compaction or flush; throughput bounded by single core |
| fsync on every write | Guarantees durability after every put() | 1–5ms latency per write on HDD; ~100µs on NVMe SSD |
| No block cache | Reads always go to disk (or OS page cache) | Repeated reads for the same key are not amortized at the engine level |
| Key-value separation | Write amplification reduced to ~2× for the sort path | Point reads require an extra VLog seek; range scans are expensive |
| No WAL group commit | Simpler implementation | Each put() pays the full fsync cost independently |
Running It
How to Use AccretionDB
The engine ships with a real-time observability dashboard — the same class of operational tooling that production engines like RocksDB and TiKV expose. Implemented as a minimal HTTP server built on raw POSIX/Winsock2 sockets (~300 lines of C++, zero external dependencies).
Live Demo
AccretionDB Testing Arena
A deployed instance of the engine with the full observability dashboard. Run benchmarks, inspect the LSM tree state, fire put/get/delete commands via the interactive console — all live.
Docker (Recommended)
# Build the image docker build -t accretiondb . # Run the dashboard docker run -p 8080:8080 accretiondb # With persistent data volume docker run -p 8080:8080 \ -v accretiondb_data:/app/acdb_production \ accretiondb # Or use Docker Compose docker compose up -d # http://localhost:8080
Build from Source
# Requires g++ with C++20 support # (mingw-w64, gcc 13+, or clang 16+) mingw32-make # Windows (MinGW) make # Linux / macOS # Start the dashboard ./acdb.exe web # Windows ./acdb web # Linux / macOS # Custom port (optional) ./acdb web 9090 # Open in browser # http://localhost:8080
HTTP API Reference
All endpoints callable with curl. Zero external dependencies.Engine Metrics
curl http://localhost:8080/api/metrics curl http://localhost:8080/api/lsm-state
Write a Key-Value Pair
curl -X POST http://localhost:8080/api/put \
-H "Content-Type: application/json" \
-d '{"key":"hello","value":"world"}'Read a Value
curl -X POST http://localhost:8080/api/get \
-H "Content-Type: application/json" \
-d '{"key":"hello"}'Delete (tombstone) + Benchmark
curl -X POST http://localhost:8080/api/delete \
-d '{"key":"hello"}'
curl -X POST http://localhost:8080/api/bench \
-d '{"type":"random_write","ops":500}'Dashboard Panels
Write Amp Gauge
Real-time ratio: storage bytes / user bytes. Bounded at ~2.0× by WiscKey architecture.
Read Amp Gauge
(SST searches + VLog reads) / get() calls. Bloom filters drive this toward 1.0×.
LSM Tree State
Live count of Memtable entries, L0/L1 SSTable files, compaction pressure %, flush proximity bar.
Bloom Filter Detail
SSTables considered, bloom skips, actual binary searches executed, skip rate percentage.
Engine Health
WAL taint status, memtable fill %, L0 compaction pressure, overall health indicator.
Interactive Console
put, get, del commands that fire HTTP API calls and display results with live metric refresh.
Benchmark Runner
Trigger random_write / sequential_write / random_read / mixed workloads (up to 2,000 ops).
Railway Deploy
GitHub Actions CI/CD auto-deploys to Railway on push to main. Fork → secrets → push.
Next Case
OrionScheduler