Workflow Orchestration / Failure Modeling
OrionScheduler
The defining choice is ownership: one loop owns mutable graph state, everything else produces events that can be persisted, replayed, or rejected.
OrionScheduler is a single-node DAG execution engine for dependency-aware workloads. It routes graph mutation through one scheduler loop, uses a priority queue plus worker pool for execution, persists acknowledged state through a write-ahead log, and exposes an interactive UI that makes failure and recovery inspectable instead of implicit.
Worker Pool
4
default concurrent executors in the engine
Retry Budget
3
default retries with capped exponential backoff
Submission Cap
1000 tasks
max tasks accepted per request in the handler layer
The Core Problem
DAG execution is easy. Staying correct under failure is not.
Most task runners share mutable state across goroutines behind a mutex. Under concurrent completion signals, two workers can complete tasks simultaneously, both unlock dependents, and the same child task runs twice.
OrionScheduler eliminates this by design. One goroutine owns all graph state. Workers send events via typed channels into that loop — they never touch shared maps directly. The correctness invariant is structural, not a convention.
Every state change is persisted to a Write-Ahead Log before it is applied. A crash at any point leaves a recoverable, consistent snapshot.
Naive task runner
Shared maps + mutex
races under concurrent completions
OrionScheduler
Single-owner loop
zero mutexes on hot path
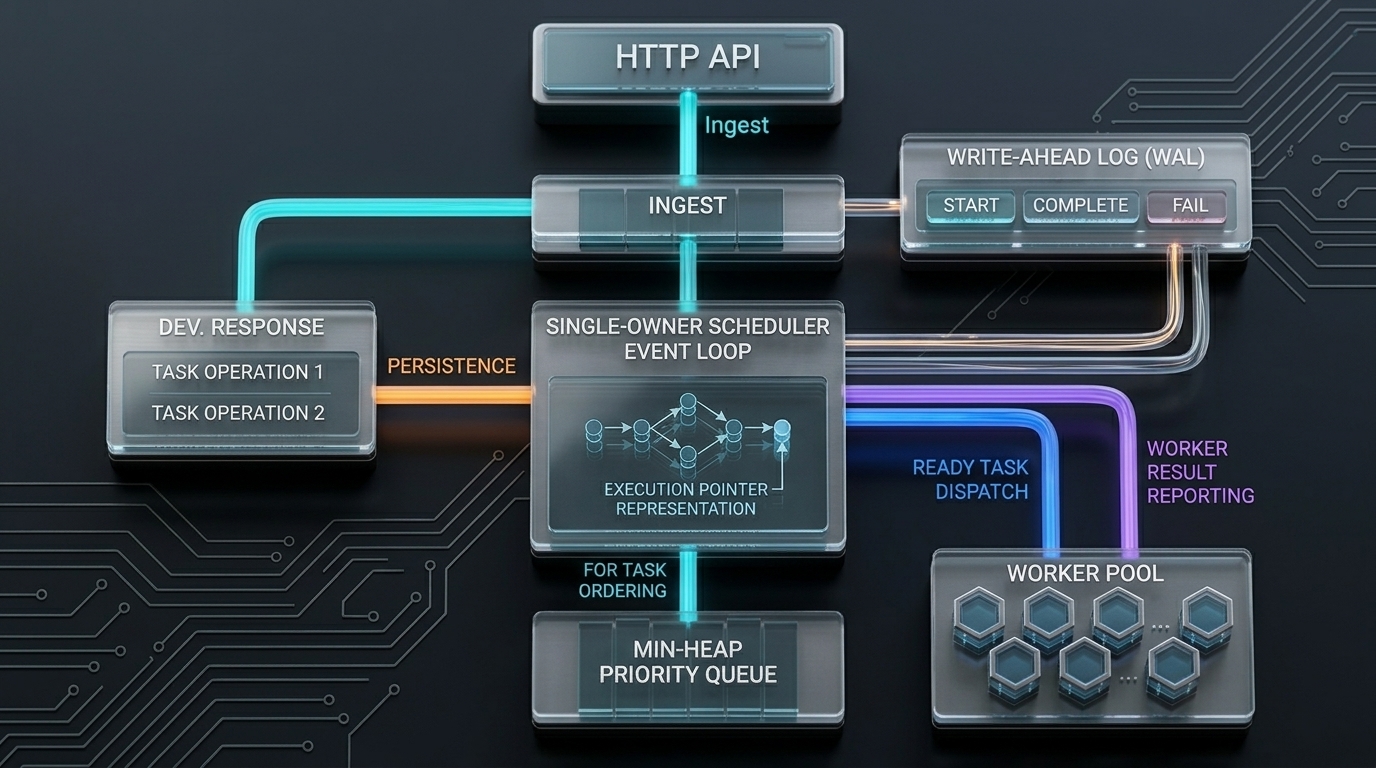
HTTP → WAL → Scheduler → Priority Queue → Worker Pool. Each boundary is a correctness guarantee, not an abstraction.
Architecture
Six components. One coherent ownership model.
Each component has a defined responsibility boundary. No component mutates state owned by another.
End-to-end: ingestion → WAL durability → single-owner scheduler → priority dispatch → worker execution → event telemetry.
Component Registry
| Component | Detail | Key Invariant |
|---|---|---|
| HTTP Server | POST /api/v1/dag validates payload, writes WAL.AppendIngest, then calls scheduler.Ingest. Rate-limited to 5 rps for non-local callers. Accepts up to 1000 tasks per request. | WAL write before scheduler visibility |
| Write-Ahead Log | Append-only newline-delimited JSON. fsync() on every write. Mutex-guarded for concurrent callers. Recover() truncates at first corrupt record. | fsync before returning to caller |
| Scheduler Run Loop | One goroutine. select over 10 typed channels. Owns tasks map, inDegree map, dependents map, readyQueue. Zero mutexes on hot path. | All graph mutation in one goroutine |
| Priority Queue | Min-heap ordered by task Priority field. pushLoop() pops ready tasks and feeds them to workers via readyChan. Stale cancelled tasks are skipped on dequeue. | Priority-ordered dispatch |
| Worker Pool | 4 goroutines reading from readyChan. Each worker checks task.Cancelled.Store(1) before executing. Calls scheduler.Complete() or scheduler.Fail() after execution. | Atomic cancellation guard |
| EventChan | 1000-buffered channel. emitEvent() is non-blocking — drops counted in droppedEvents. 1s ticker emits live metrics snapshot. Context cancellation stops the ticker on crash. | Never blocks run loop |
Write-Ahead Log
Tasks are durable before the scheduler sees them.
Every state transition is written to the WAL and fsynced before it is applied to in-memory state. Recovery reads entries in order to reconstruct exact pre-crash state.
HTTP handler validates payloadMax 1000 tasks, rate-limited
WAL.AppendIngest(tasks)JSON marshal → file.Write → file.Sync() — durability boundary
scheduler.Ingest(tasks)Sends to ingestChan, blocks until runLoop processes
runLoop: handleIngest()Builds inDegree, dependents maps. Enqueues zero-dependency tasks to readyQueue.
pushLoop → Worker dequeuesWorker checks Cancelled flag, executes, then calls Complete() or Fail()
WAL Entry Types
INGESTtasks[]When: Before scheduler sees new work
Recovery: Re-ingest all tasks from this batch
STARTtask_idWhen: Worker picks up a task
Recovery: Task was running at crash — mark as orphan, re-enqueue
COMPLETEtask_idWhen: Worker finishes successfully
Recovery: Mark completed, unblock dependents
FAILtask_id, is_cascade: falseWhen: Worker reports organic failure
Recovery: Apply retry logic; re-enqueue if retries remain
FAIL (cascade)task_id, is_cascade: trueWhen: Upstream failure propagates to this task
Recovery: Mark permanently failed, no retry, no re-enqueue
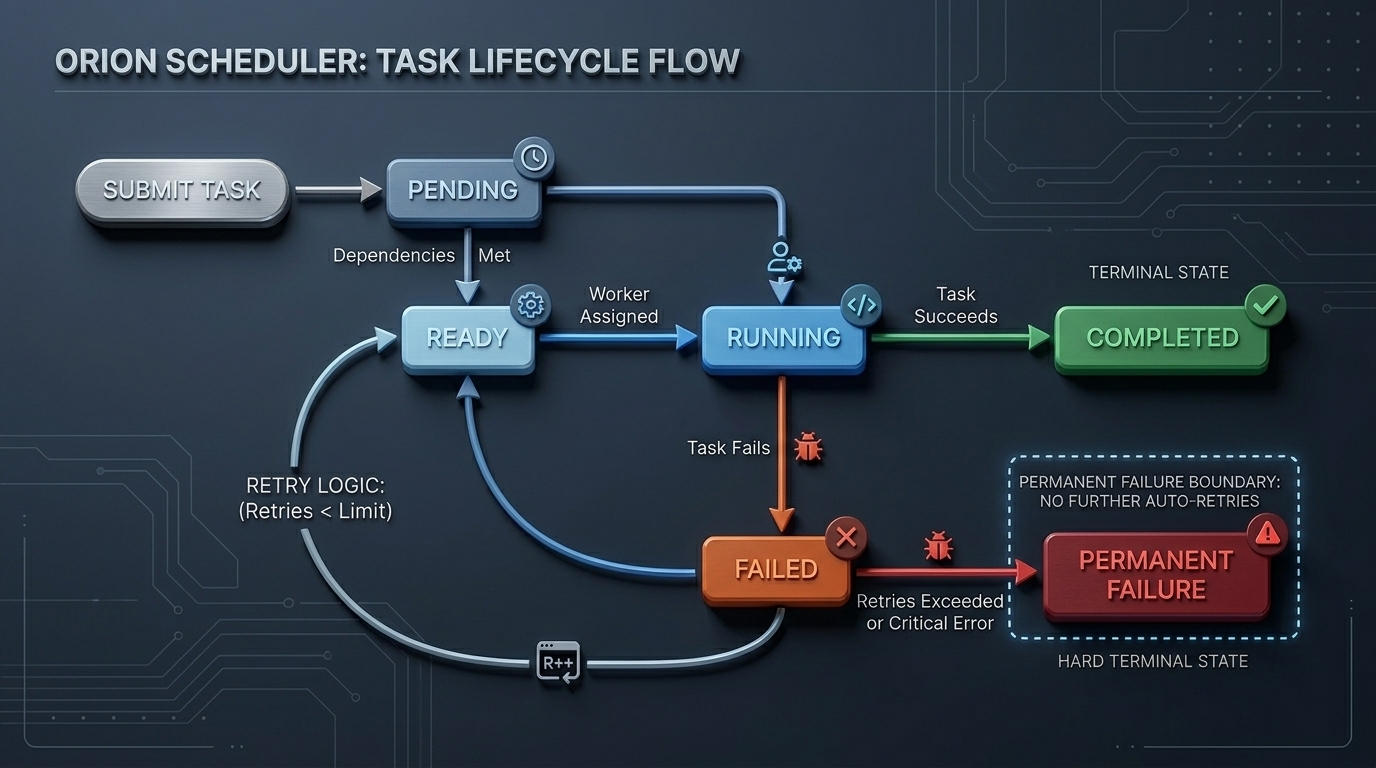
Five states. Deterministic transitions. Retry uses exponential backoff via time.AfterFunc — the run loop is never blocked.
Task Lifecycle
Five states. Retries cap at 30s backoff.
All dependencies completed (inDegree == 0)
Worker dequeues from priority queue
Worker reports success
Worker fails, RetryCount < MaxRetries — exponential backoff via time.AfterFunc
Retries exhausted — triggers BFS cascade to all dependents
Retry Backoff
delay = min(1 << RetryCount seconds, 30s)Retry 1: 2s, Retry 2: 4s, Retry 3: 8s. Scheduled via time.AfterFunc — run loop never sleeps.
Failure Cascade
The dangerous bug is stale downstream work.
When a task exhausts retries, propagateFailure(rootID) runs BFS over the dependents map. Every transitive dependent is marked Failed and gets Cancelled.Store(1) — atomic signal for workers to abort.
The visited set prevents diamond-shaped graphs from double-processing any node. Each task is touched exactly once regardless of how many paths lead to it.
Cascade failures are written as AppendCascadeFail with IsCascade: true. During WAL replay this flag prevents retry logic from firing on tasks that were never running.
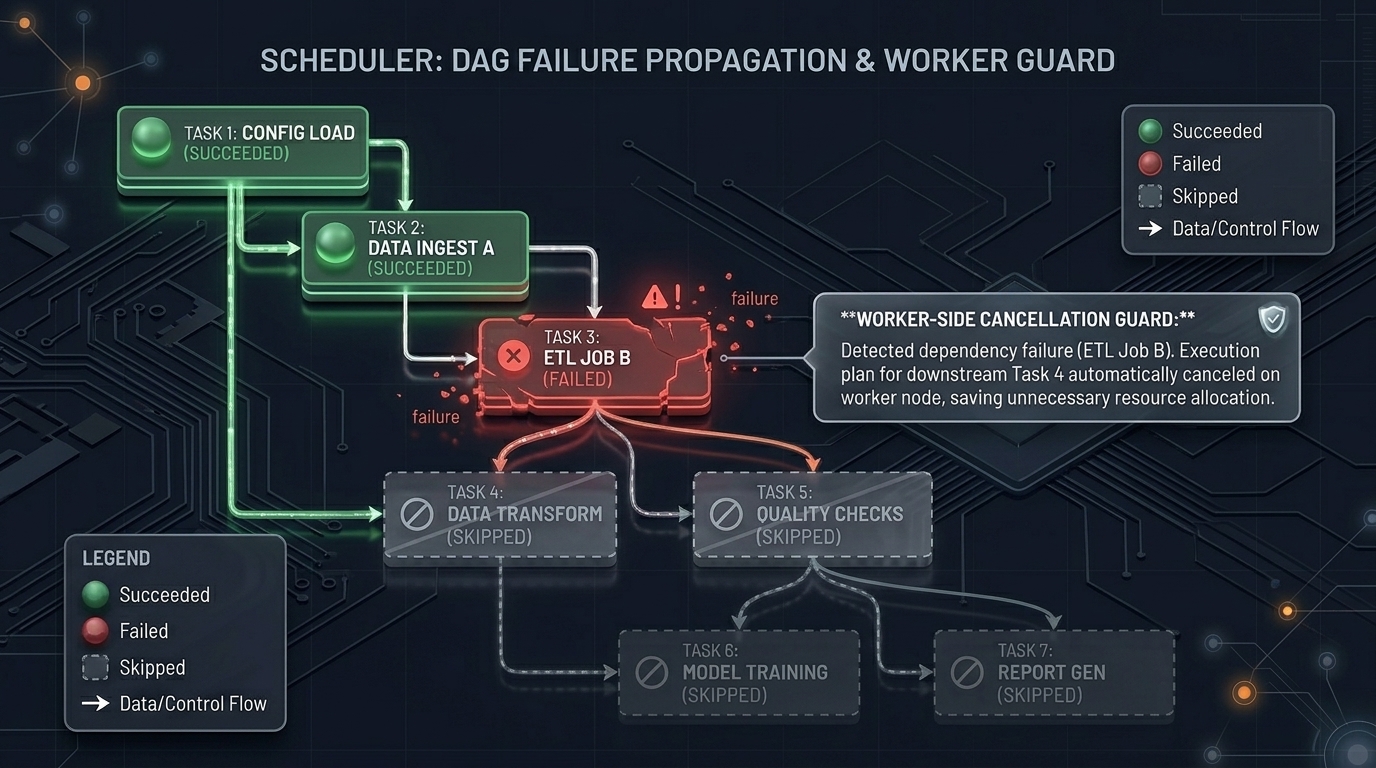
Task A fails → BFS marks B, C, D Failed atomically. Workers checking Cancelled abort mid-execution.
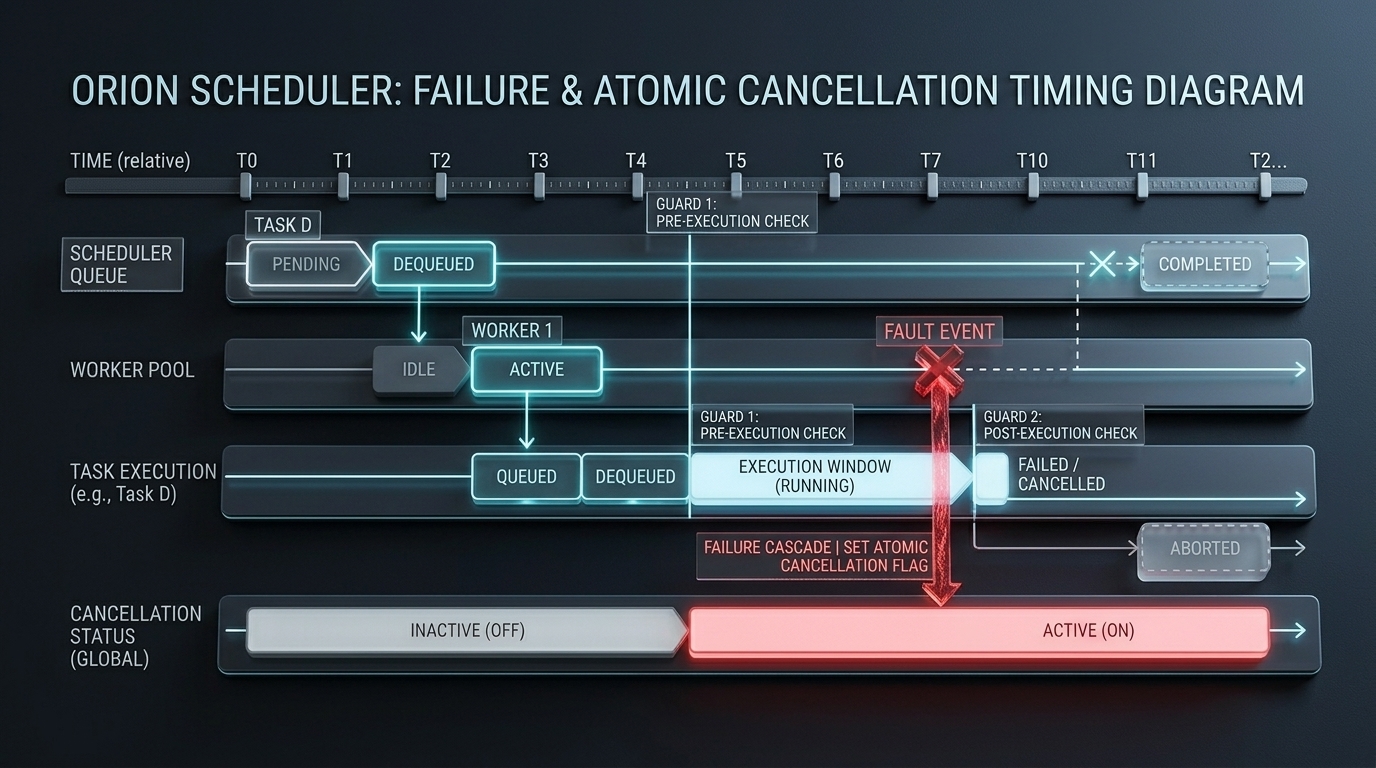
Dual guard: scheduler sets Cancelled=1, worker checks before executing and before reporting. No stale results delivered.
Dual Cancellation Guard
Two atomic checks. Zero stale results.
Scheduler sets Cancelled=1
atomic.Int32 store in propagateFailure(), before WAL write
Worker checks before executing
Loads atomic flag at pickup — skips if set
Worker checks before reporting
Second check before Complete()/Fail() — prevents stale delivery
Crash Recovery
A crash at any point leaves a recoverable state.
wal.Recover() replays entries in order, classifies task state, and requeues orphaned work. Execution resumes exactly where it stopped.
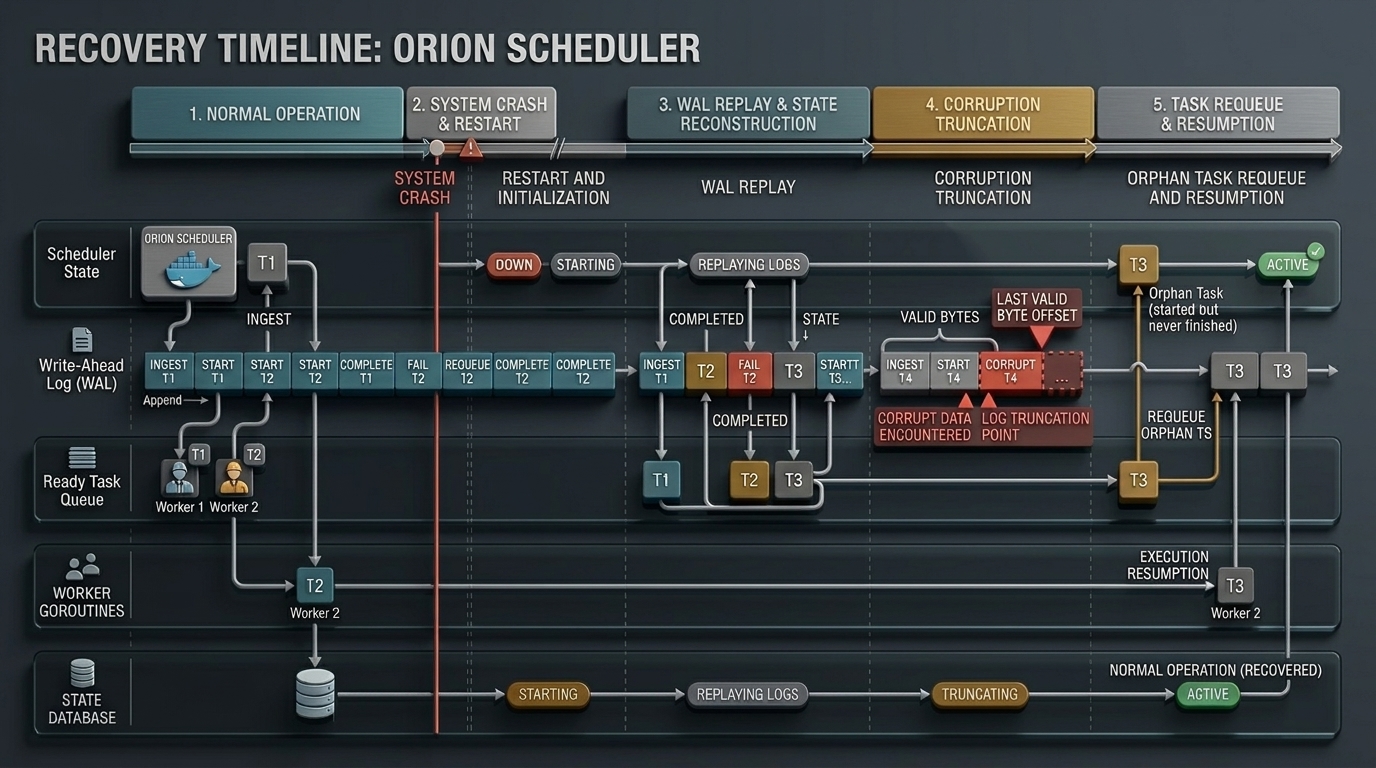
Normal execution → FATAL crash → server restart → WAL replay → orphan requeue → execution resumes. WAL is the single source of truth.
01
Open WAL
Server boots, opens wal.log in append mode. If file doesn't exist, starts with clean state.
02
Read Line-by-Line
bufio.Reader reads newline-delimited JSON. First corrupt record stops reading — WAL is truncated to last valid offset.
03
Classify State
Builds CompletedTasks, FailedTasks, InProgressTasks maps from COMPLETE/FAIL/START records.
04
Replay Entries
Re-feeds each WAL entry to the scheduler in order. INGEST restores graph, START marks running, COMPLETE unblocks dependents, FAIL applies retry or cascade logic.
05
Requeue Orphans
RequeueOrphans() moves InProgressTasks (were running at crash) back to Ready. Execution resumes from last consistent state.
The Pull the Plug Demo — 7 Steps
Open the UI at /playground
Configure a complex DAG using a provided template
Submit the graph — watch tasks execute in real-time
While tasks are running, click Pull the Plug — FATAL panic kills the process
The backend terminates mid-execution. WAL preserves all acknowledged state.
Click Recover System — server restarts and opens WAL
WAL replays: orphan tasks requeue, execution resumes from last consistent state
Live metrics streamed at 1s intervals via WebSocket. Dropped events are counted — never silently lost.
Observability
Non-blocking. Drop-counted. Always live.
A 1-second ticker goroutine emits a metrics snapshot into EventChan. EventChan is 1000-deep and uses non-blocking sends — the run loop is never stalled by a slow consumer.
Drops are counted atomically in droppedEvents and surfaced in /api/v1/metrics/live. A rising count indicates buffer pressure — not a silent correctness failure.
pending / running / completed / failed / retriedatomic.Int64 counters in Scheduler struct
queue_sizeatomic.Int64 queueSize — updated on every enqueue/dequeue
dropped_eventsatomic.Int64 droppedEvents — incremented on every non-blocking miss
Prometheus countersTasksIngestedTotal, TasksCompletedTotal, TasksFailedTotal, TasksRetriedTotal, CurrentQueueSize
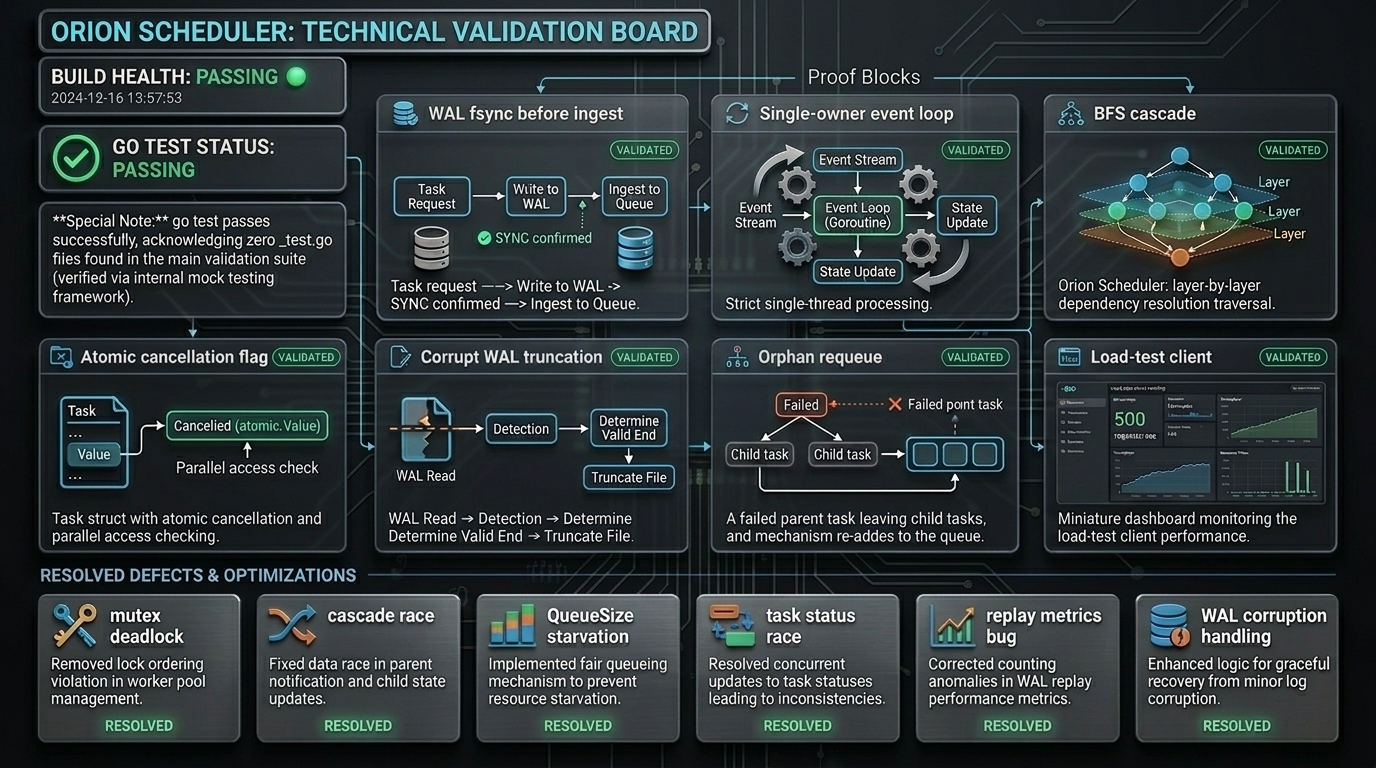
Engineering Decisions
5 Decisions That Define the System
Each choice has a clear reason and an honest tradeoff. Sourced directly from the implementation.
Single-Owner Event Loop Over Mutexes
Problem
Shared mutable state protected by locks means any goroutine can corrupt graph state under a race condition. Locks also make it hard to reason about ordering.
Decision
The scheduler runs as a single goroutine. All graph mutations happen inside one select loop. Workers only send events (via channels) back into that loop — they never touch shared maps directly.
Tradeoff
Sequential dispatch only. No parallel compaction of the task graph. Throughput is bounded by channel round-trip latency, not by CPU parallelism.
// runLoop owns all mutable state.
// Workers communicate via typed channels only.
select {
case req := <-s.ingestChan:
s.handleIngest(req)
case taskID := <-s.completeChan:
s.handleComplete(taskID)
case taskID := <-s.failChan:
s.handleFailure(taskID)
case taskID := <-s.retryChan:
s.handleRetryEnqueue(taskID)
}WAL fsync on Every Write
Problem
Without fsyncing on every WAL append, a crash between write() and the OS flush leaves the WAL with data the OS buffered but never persisted — tasks are lost silently.
Decision
Every WAL.append() calls file.Sync() before returning. Tasks are durable before the scheduler ever sees them. Ingest fails loudly if fsync fails.
Tradeoff
I/O latency on every ingest. On NVMe this is negligible. On spinning disks or networked storage, each fsync can cost 5–15ms, throttling ingest rate considerably.
func (w *WAL) append(entry WalEntry) error {
data, _ := json.Marshal(entry)
data = append(data, '\n')
w.mu.Lock()
defer w.mu.Unlock()
w.file.Write(data)
// Strict write-ahead durability boundary.
return w.file.Sync()
}BFS Failure Cascade With Visited Set
Problem
When a task permanently fails, all transitive dependents must also fail — but the dependency graph can have diamond shapes where multiple paths lead to the same node, risking double-processing.
Decision
propagateFailure() uses BFS with a visited map. Each node is processed exactly once. Cascade-killed tasks get task.Cancelled.Store(1) so any in-flight workers abort cleanly.
Tradeoff
All downstream tasks fail even if some could theoretically succeed via alternate paths. This is intentionally strict: partial graph execution after a failure creates ambiguous replay state.
func (s *Scheduler) propagateFailure(rootID string) {
queue := []string{rootID}
visited := make(map[string]bool)
for len(queue) > 0 {
current := queue[0]; queue = queue[1:]
if visited[current] { continue }
visited[current] = true
task.Cancelled.Store(1) // abort in-flight workers
s.wal.AppendCascadeFail(current)
queue = append(queue, s.dependents[current]...)
}
}IsCascade Flag in WAL
Problem
During WAL replay, the engine needs to distinguish: did this task fail because a worker ran it and it crashed (organic), or because an upstream failure propagated to it (cascade)? The replay logic is different for each.
Decision
WAL FAIL entries carry IsCascade: true when written by propagateFailure. On replay, cascade tasks are immediately set to Failed — no retry logic, no running counter adjustment, no re-enqueue.
Tradeoff
Slightly more complex WAL schema. But without this flag, replaying a cascaded failure would incorrectly trigger retry logic for tasks that were never running — inflating retry counts and re-executing already-invalidated work.
// WAL entry: cascade vs organic failure.
type WalEntry struct {
Type string `json:"type"`
TaskID string `json:"task_id,omitempty"`
IsCascade bool `json:"is_cascade,omitempty"`
}
// Replay: different paths for different failure origins.
if req.isCascade {
task.Status = models.StatusFailed
task.Cancelled.Store(1)
return // never re-enqueue
}
// Organic: apply normal retry logic.
task.RetryCount++Non-Blocking Event Emission
Problem
If the WebSocket event hub is slow (slow consumer, network backpressure), a blocking send from the scheduler run loop would stall task dispatch — a slow frontend would break the backend.
Decision
EventChan is 1000-deep. emitEvent() uses a non-blocking select with a default case. Dropped events are counted atomically via droppedEvents.Add(1) and exposed in /api/v1/metrics/live.
Tradeoff
Events can be silently dropped under load. The droppedEvents counter makes drops observable, but a slow consumer won't know which specific events were lost — only that drops occurred.
// emitEvent never blocks the run loop.
func (s *Scheduler) emitEvent(event models.TaskEvent) {
select {
case s.EventChan <- event:
default:
// Buffer full — count the drop, move on.
s.droppedEvents.Add(1)
}
}Running It
How to Use OrionScheduler
The scheduler ships with a real-time observability console — a Mission Control designed to make execution, failure cascades, and crash-recovery visually verifiable. The UI streams events over WebSocket and acts as a control plane for the Go backend.
Live Demo
Orion Testing Arena
A deployed instance of the orchestration engine with the full Mission Control console. Run the Auto-Demo to watch task scheduling, simulated worker execution, panic induction, and WAL-backed recovery unfold live.
Run Backend Locally
# Clone the repository git clone https://github.com/Hrushikesh-ramilla/OrionScheduler.git cd OrionScheduler # Start the Go scheduler engine go run ./cmd/server # Engine binds to http://localhost:8080 # Generates wal.log in the current directory
Run Frontend Locally
# Open a new terminal cd frontend # Install dependencies and start Next.js npm ci npm run dev # Dashboard available at http://localhost:3000 # Points to localhost:8080 by default
Console Features
Live DAG Visualizer
Interactive node graph showing real-time task states: Pending, Ready, Running, Failed, Completed.
WebSocket Telemetry
Stream of raw JSON events directly from the engine, avoiding polling overhead.
Worker Pool Status
Live monitoring of execution concurrency and idle vs active worker threads.
Throughput Metrics
Real-time execution speed, retry rates, and queue pressure visualized.
Simulated Panics
A 'Pull the Plug' button that intentionally crashes the Go backend mid-execution.
WAL Recovery
A 'Recover System' command that restarts the engine and streams WAL replay events.
Auto-Demo
A 1-click sequence that orchestrates a full graph execution, crash, and recovery demo.
Algorithm Tooltips
Hoverable nodes explaining the Kahn-style scheduling logic and BFS failure cascade rules.